
The Illustrated Transformer — 中文译文
| 📘 | 2025 更新:作者已将本文扩展成书。书中第 3 章涵盖 Multi-Query Attention、RoPE 位置编码等七年来的演进。 |
在上一篇文章里,我们看了注意力(Attention)——现代深度学习里无处不在的机制。Attention 显著提升了神经机器翻译的效果。本文聚焦 Transformer:一种用注意力大幅加速训练的模型。它在特定任务上超过了 Google 的神经机器翻译模型;更大的好处在于易于并行化——Google Cloud 也推荐用 Transformer 作为 Cloud TPU 的参考模型。下面我们把模型拆开,看它如何工作。
Transformer 出自论文 Attention Is All You Need。TensorFlow 实现见 Tensor2Tensor;哈佛 NLP 组有带 PyTorch 的逐段注解。本文会适度简化,按概念循序渐进,方便没有深厚背景的读者理解。
2025 更新:作者制作了免费短视频课程(含动画):
先把模型想象成一个黑盒:在机器翻译里,输入一种语言的句子,输出另一种语言的译文。
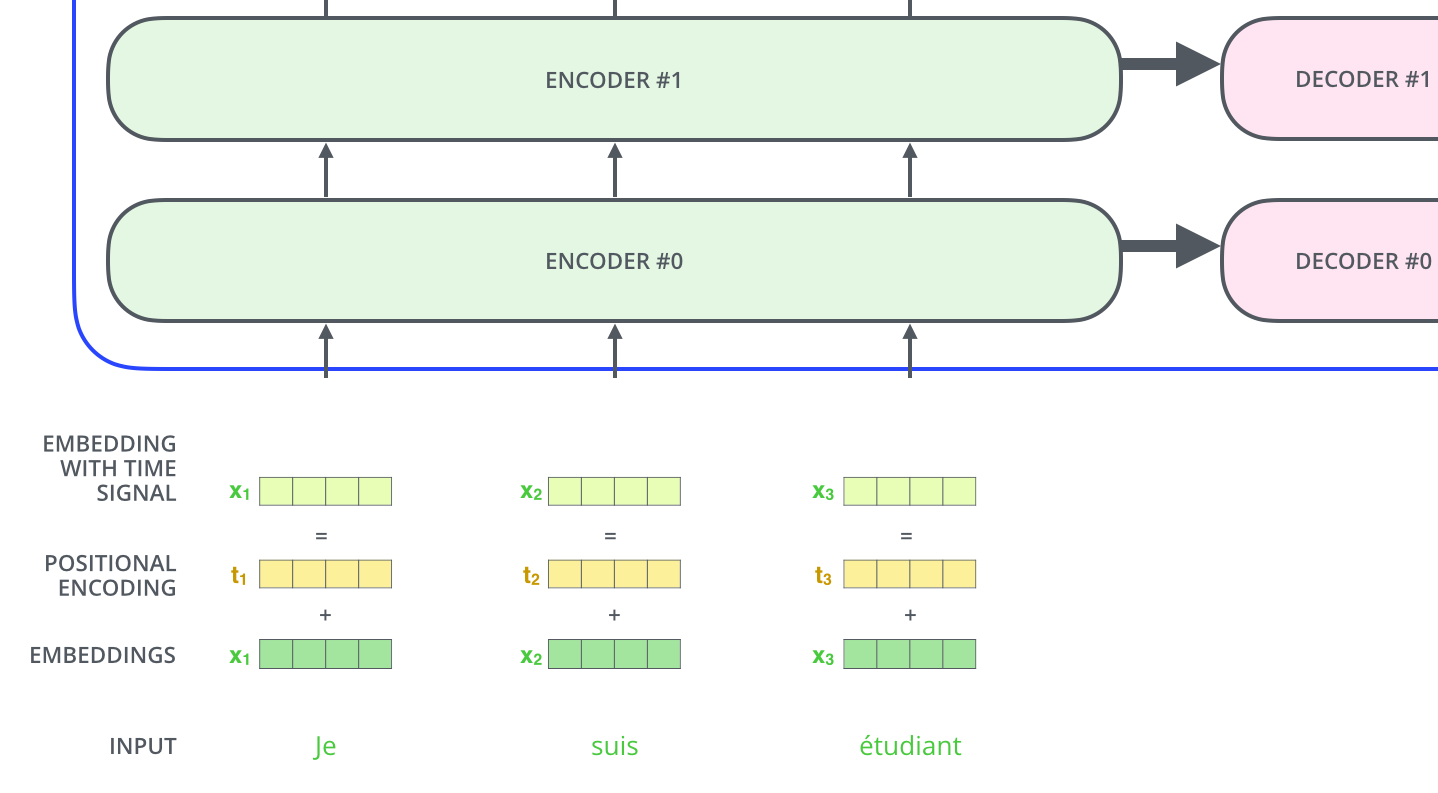
打开黑盒,可见编码器、解码器以及二者之间的连接。
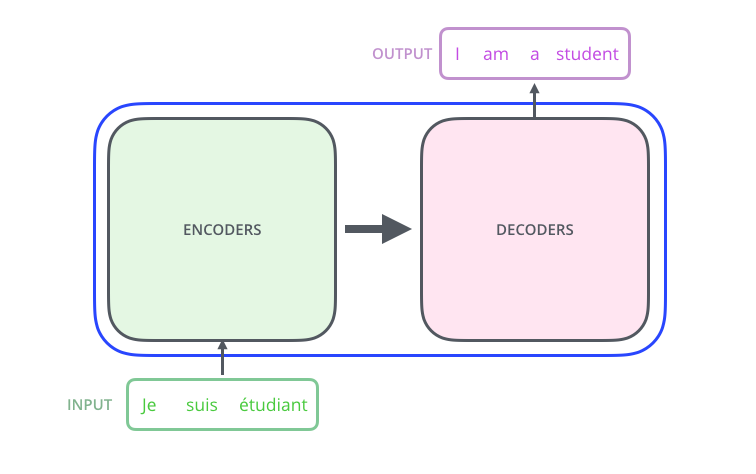
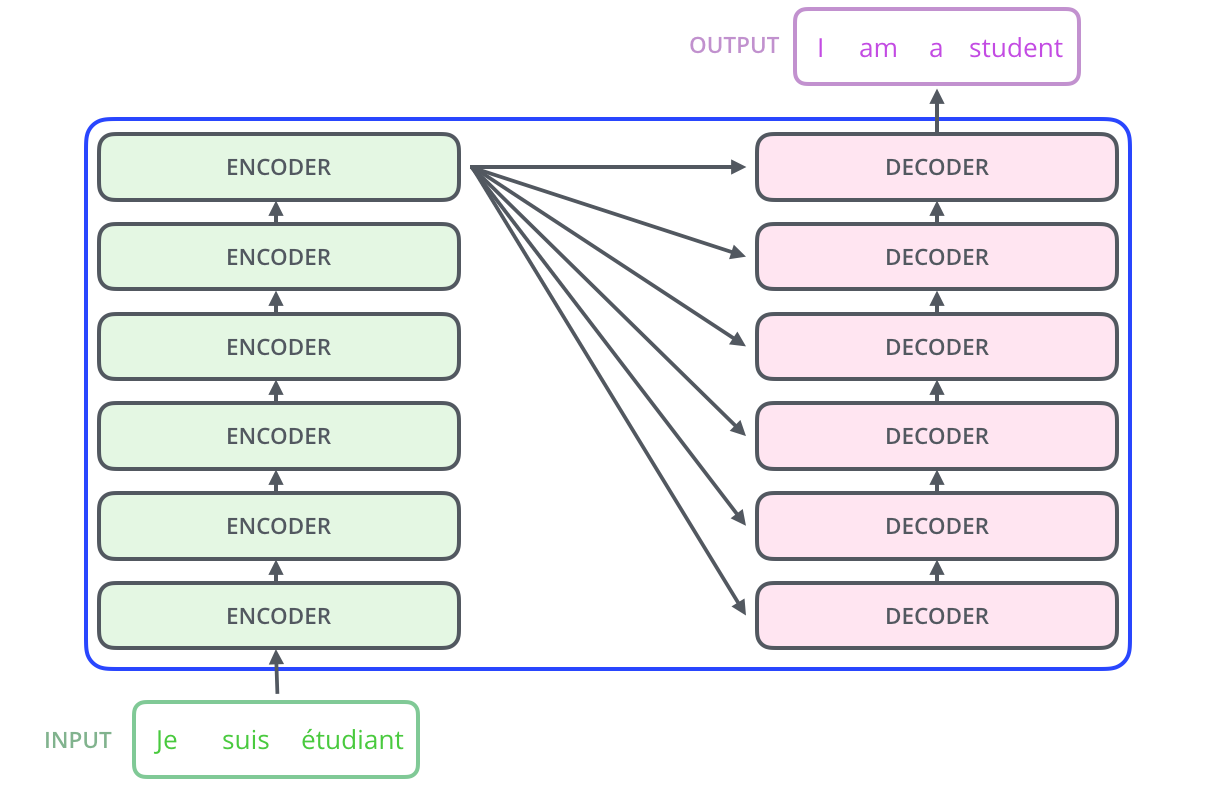
编码器是一叠 encoder(论文里堆了 6 层——数字 6 并无魔法,可实验其他深度);解码器是同样数量的 decoder 堆叠。
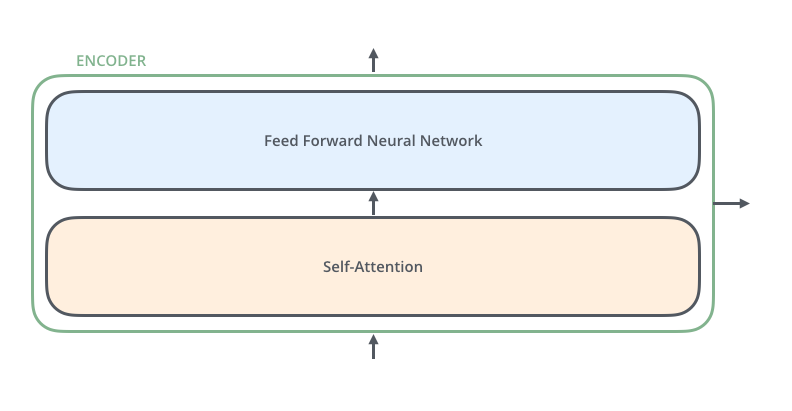
各 encoder 结构相同但权重不共享。每个 encoder 有两层子模块:
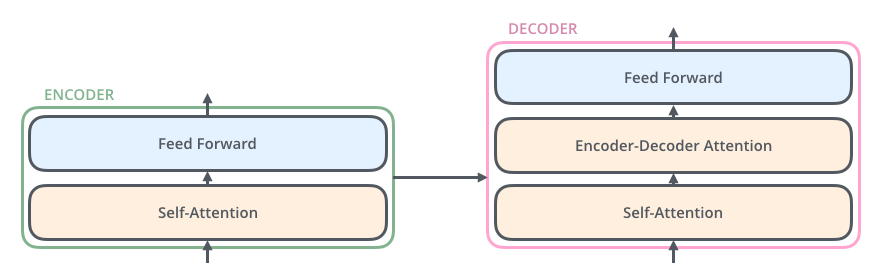
Decoder 也有这两层,中间还夹一层编码器-解码器注意力,帮助 decoder 聚焦输入句的相关部分(类似 seq2seq 里的 attention)。
了解主要组件后,看向量/张量如何在组件间流动,把训练好的模型的输入变成输出。
与常见 NLP 流程一样,先把每个输入词用 embedding 变成向量。

Embedding 只在最底层 encoder 发生。更上层的 encoder 接收的是列表:每个元素是 512 维向量——底层是词嵌入,上层则是下一层 encoder 的输出。列表长度是超参数,通常取训练集最长句长。
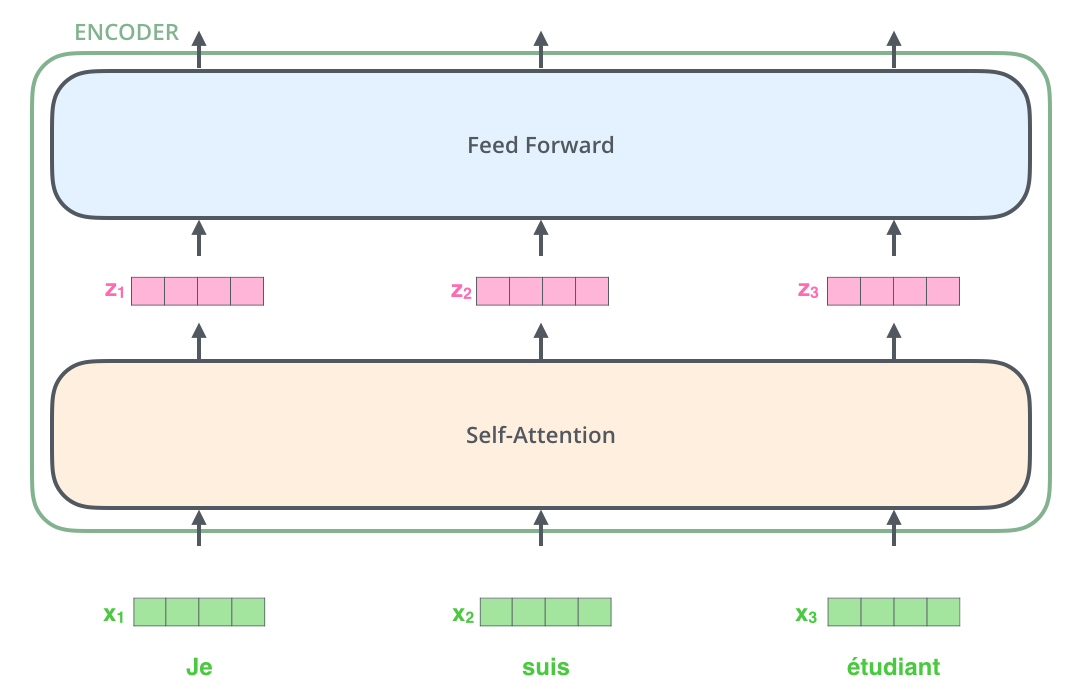
嵌入后,每个词依次流过 encoder 的两层子模块。
Transformer 的一个关键性质:每个位置的词在 encoder 里有自己的路径。自注意力层里路径之间有依赖;FFN 没有,因此流过 FFN 时各路径可并行执行。
下面换一句更短的例子,看 encoder 每个子层里发生什么。
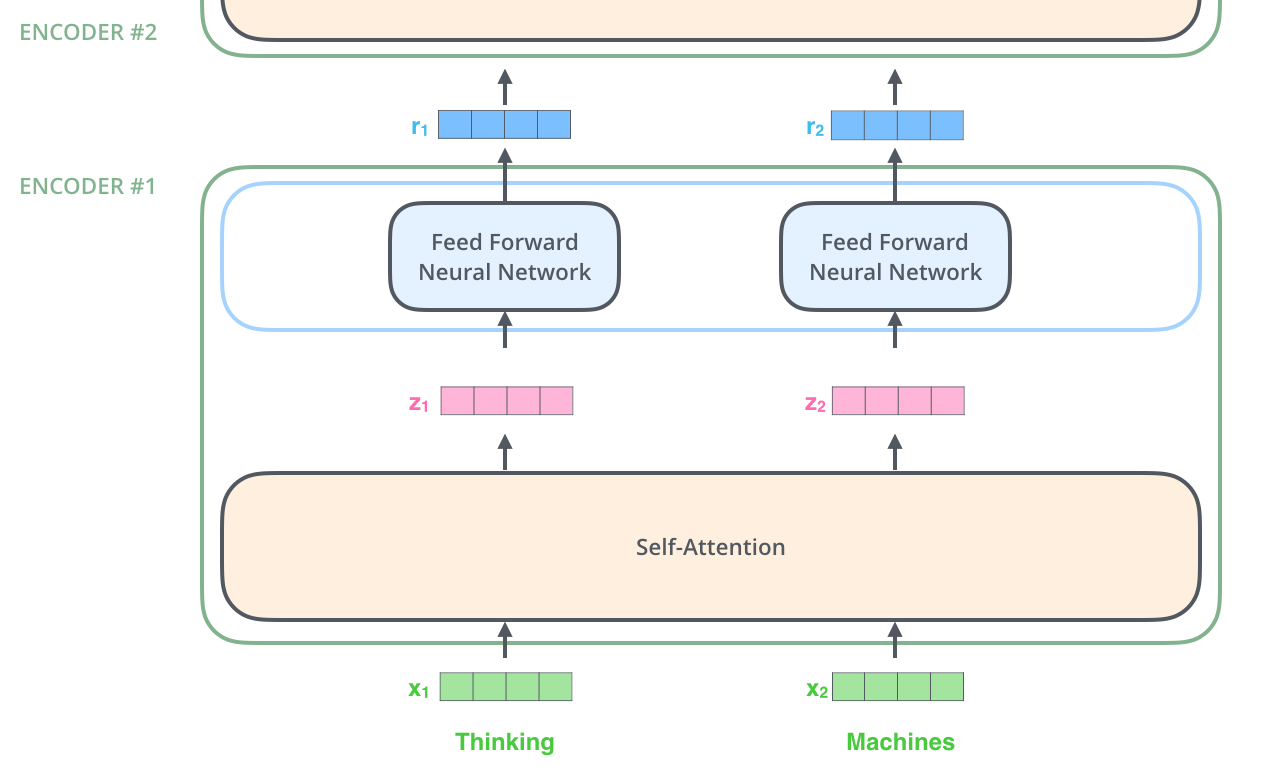
Encoder 接收向量列表,先过自注意力,再过 FFN,再把输出传给上一层 encoder。
别被「自注意力」吓到——作者本人也是读到 Attention Is All You Need 才第一次接触。核心直觉如下。
假设输入句是:
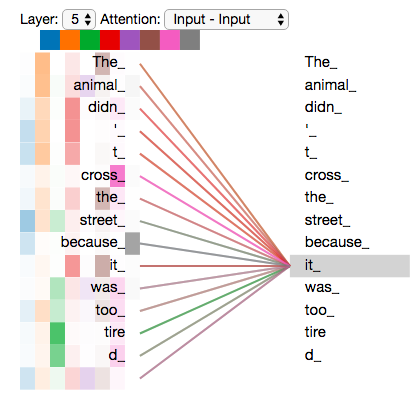
The animal didn't cross the street because it was too tired句中的 it 指什么?街还是动物?对人简单,对算法不简单。
处理 it 时,自注意力让模型把它与 animal 关联起来。处理每个位置时,模型都可以看序列中其他位置,以得到更好的表示。
若熟悉 RNN:隐状态把「之前处理过的词」融入当前词。自注意力是 Transformer 用来把「其他相关词的理解」烘焙进当前词的方法。

it 时,注意力机制聚焦 The Animal,并将其表示的一部分融入 it 的编码可在 Tensor2Tensor notebook 加载 Transformer 并交互查看注意力。
先看用向量怎么算,再看矩阵实现。
第 1 步:从每个输入向量(词嵌入)生成三个向量:Query(Q)、Key(K)、Value(V)——分别乘以训练得到的权重矩阵 WQ、WK、WV。
这些向量维度是 64,而嵌入是 512——这是架构选择(便于多头注意力计算量大致恒定),并非必须更小。
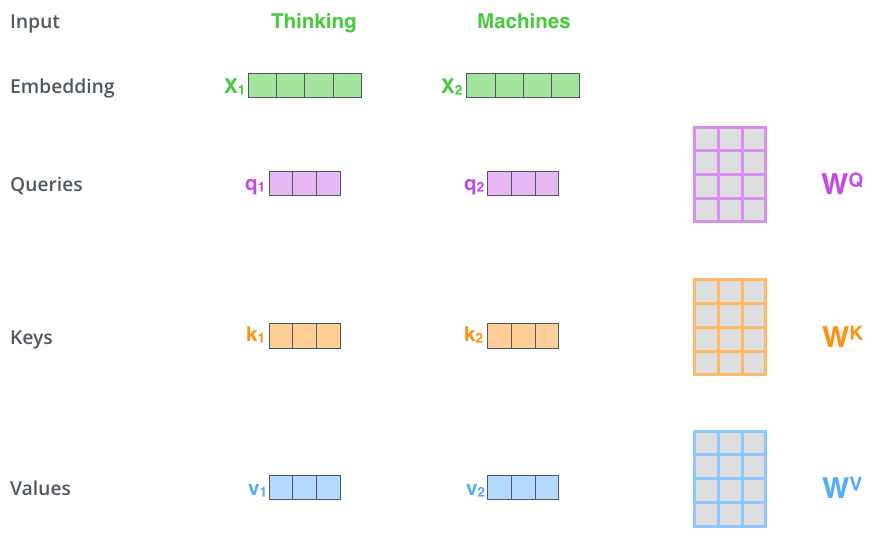
Q/K/V 是便于计算与思考的抽象;看完下面步骤就明白各自角色。
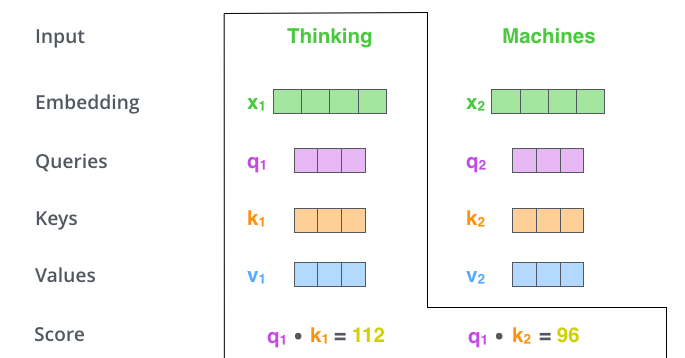
第 2 步:算分数。例如为第一个词「Thinking」算自注意力:用它的 query 与句中每个词的 key 做点积,得到「该位置应关注其他位置多少」的分数。
第 3、4 步:分数除以 8(key 向量维度 64 的平方根,使梯度更稳定),再经 softmax,得到非负且和为 1 的权重。

当前位置的词通常权重最高,但有时也需要关注其他相关词。
第 5 步:用 softmax 权重乘以各 value 向量——想保留的词权重大,无关词被压到接近 0。
第 6 步:加权求和 value,得到该位置自注意力层的输出。

自注意力计算到此结束,结果向量送入 FFN。实际实现用矩阵批量计算,见下一节。
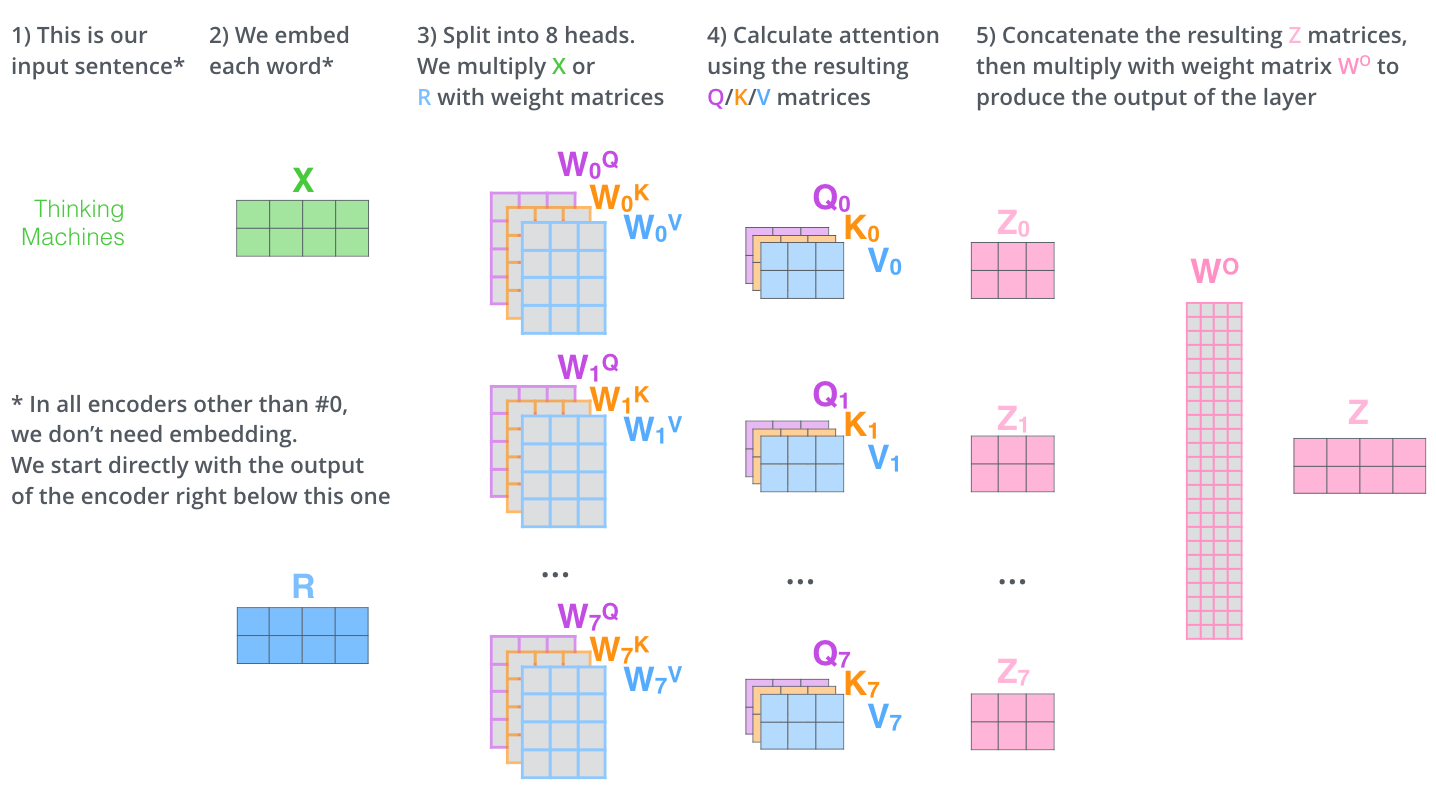
第 1 步:把嵌入打包成矩阵 X,乘以 WQ、WK、WV 得到 Q、K、V 矩阵。X 的每一行对应一个词。

合并:第 2~6 步可写成一条公式:

论文用多头注意力进一步改进自注意力,好处有二:
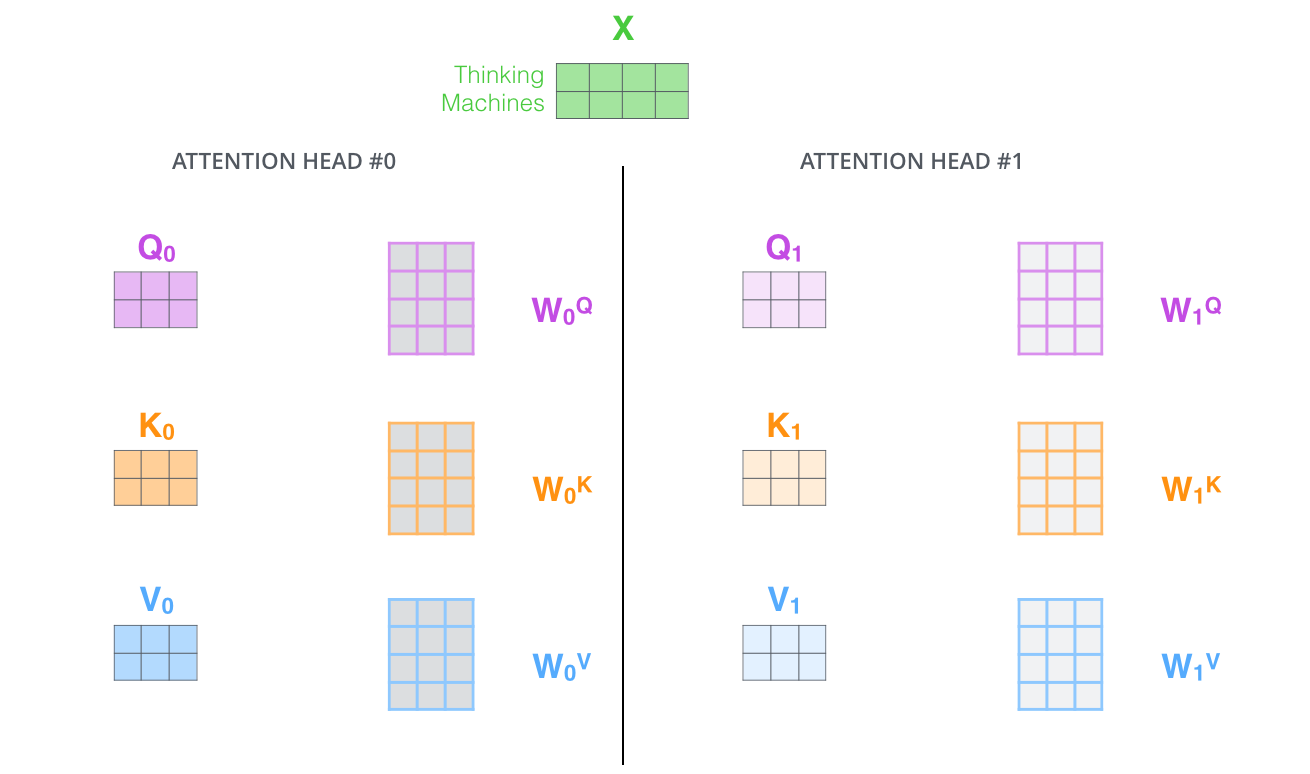
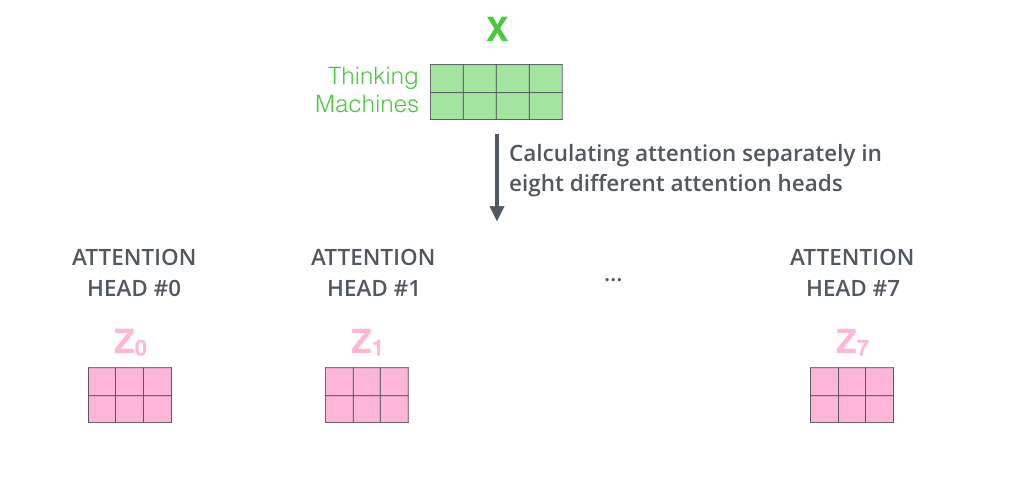
对 8 组不同权重各算一遍自注意力,得到 8 个 Z 矩阵。
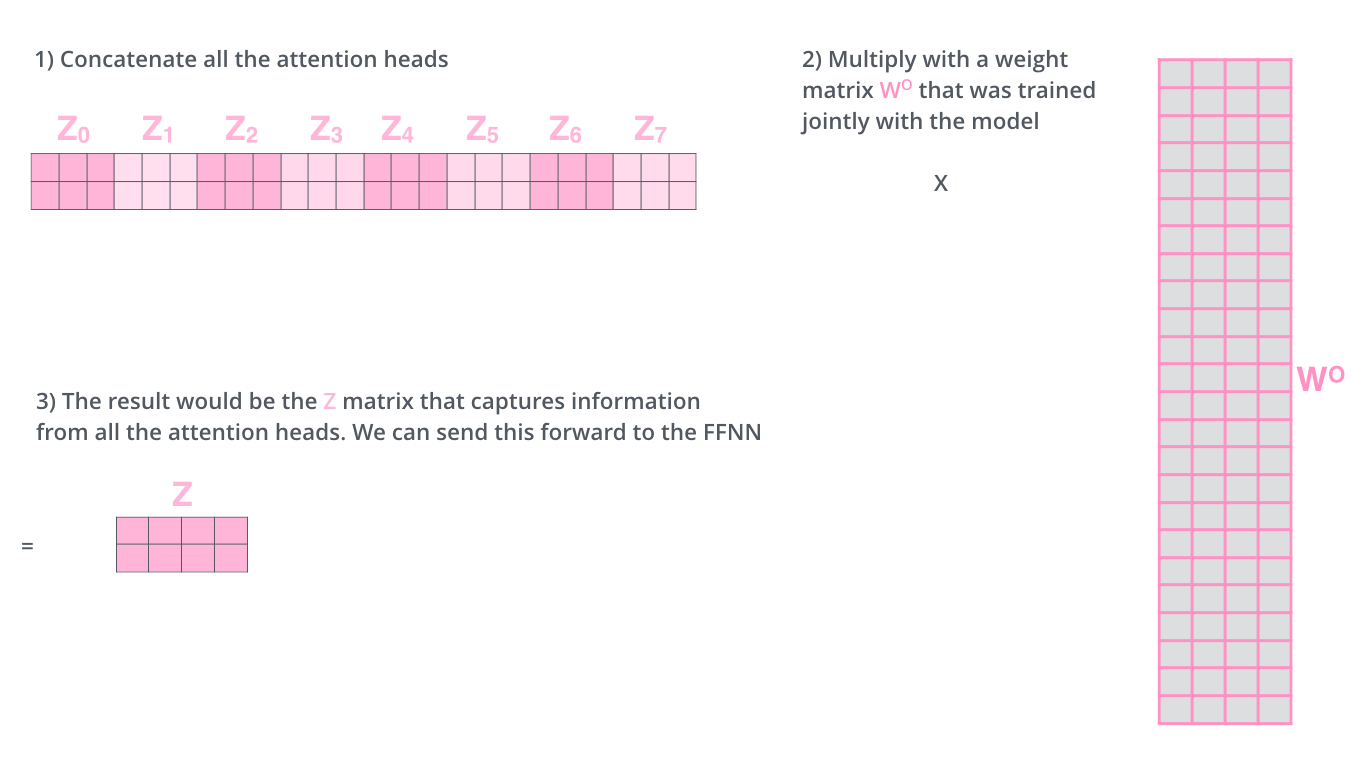
FFN 只接受一个矩阵,因此把 8 个 Z 拼接后再乘以输出权重矩阵 WO。
再看编码 it 时不同头关注哪里:一头主要关注 the animal,另一头关注 tired——it 的表示融合了二者信息。

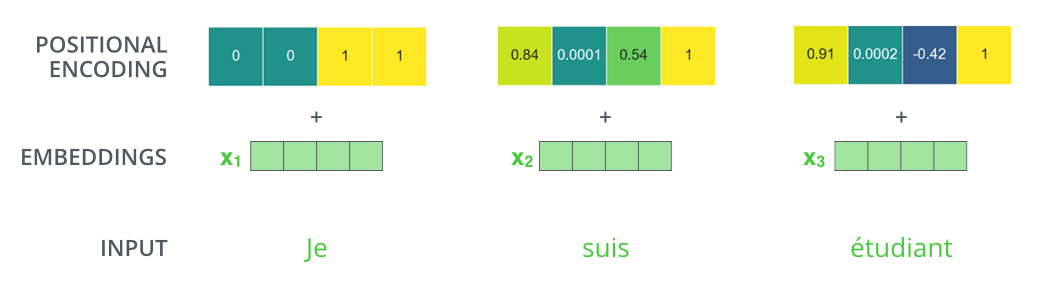
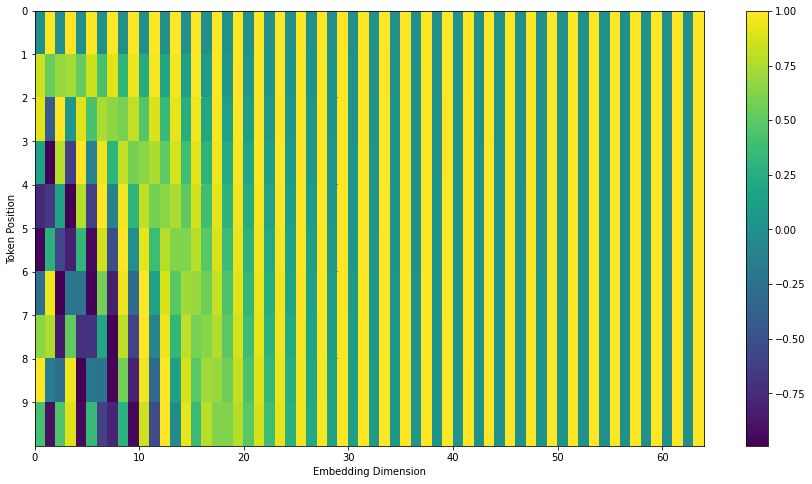
到目前为止的模型还缺少对词序的显式建模。Transformer 给每个嵌入加上一个位置编码向量,按固定模式生成,帮助模型感知位置与距离。
若嵌入维度为 4,位置编码示意如下:
真实模型里每行是一个位置的 512 维编码,数值在 -1 到 1 之间,热力图可见规律:
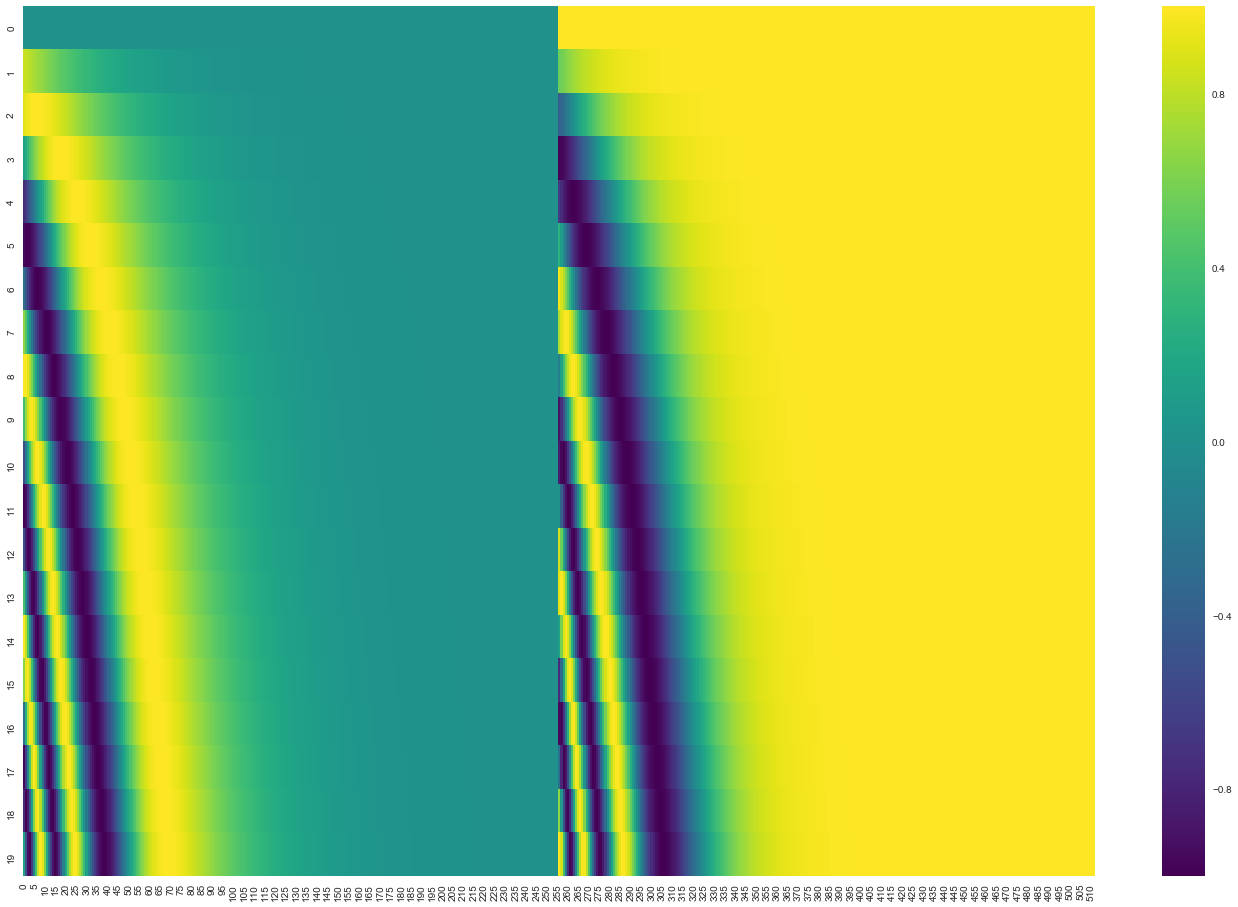
2020 年 7 月更新:上图来自 Tensor2Tensor 实现;原论文用 sin/cos 交错而非左右拼接:
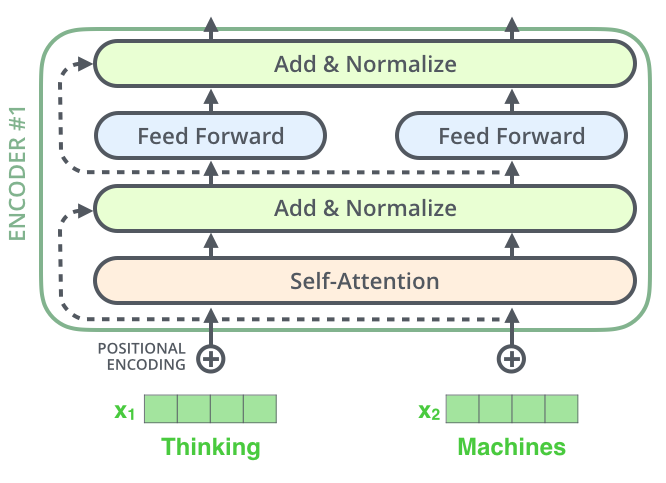
Encoder 每个子层(自注意力、FFN)外都有残差连接,并接层归一化(Layer Norm)。
Decoder 子层同理。2 层 encoder + 2 层 decoder 的完整结构示意:
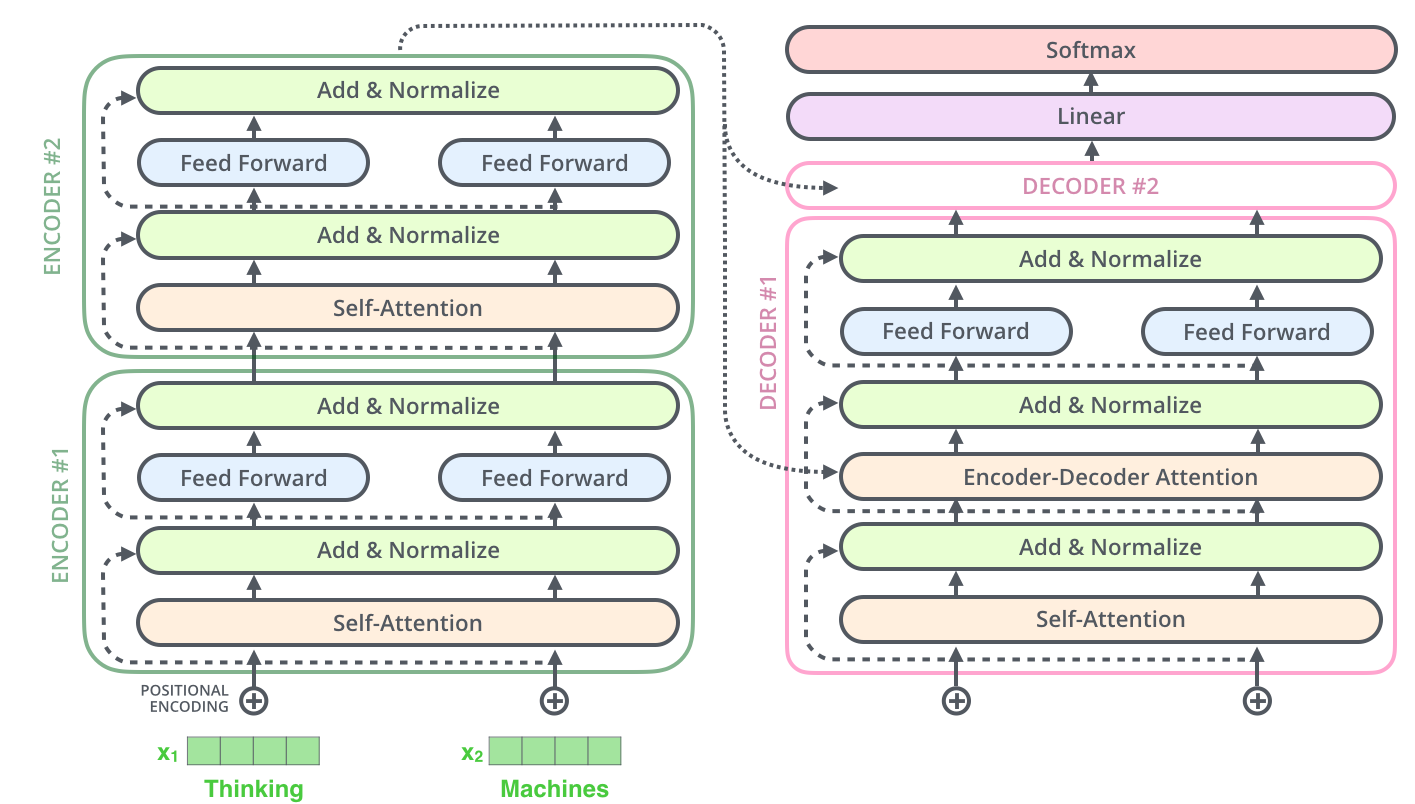
Encoder 侧概念掌握后,Decoder 组件类似;重点看它们如何协同。
Encoder 先处理输入序列;顶层 encoder 输出转为 K、V,供每个 decoder 的「编码器-解码器注意力」使用,让 decoder 聚焦输入的合适位置。
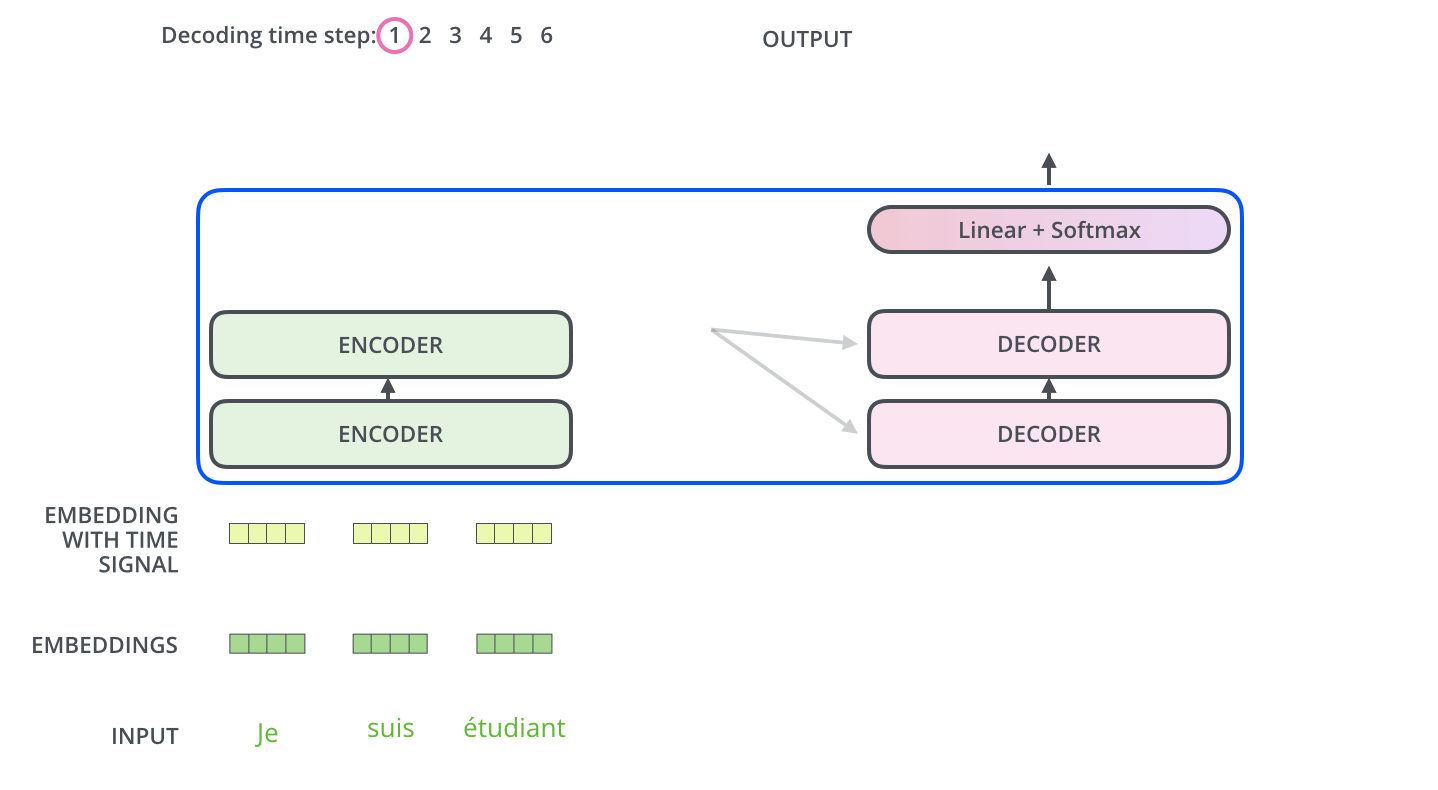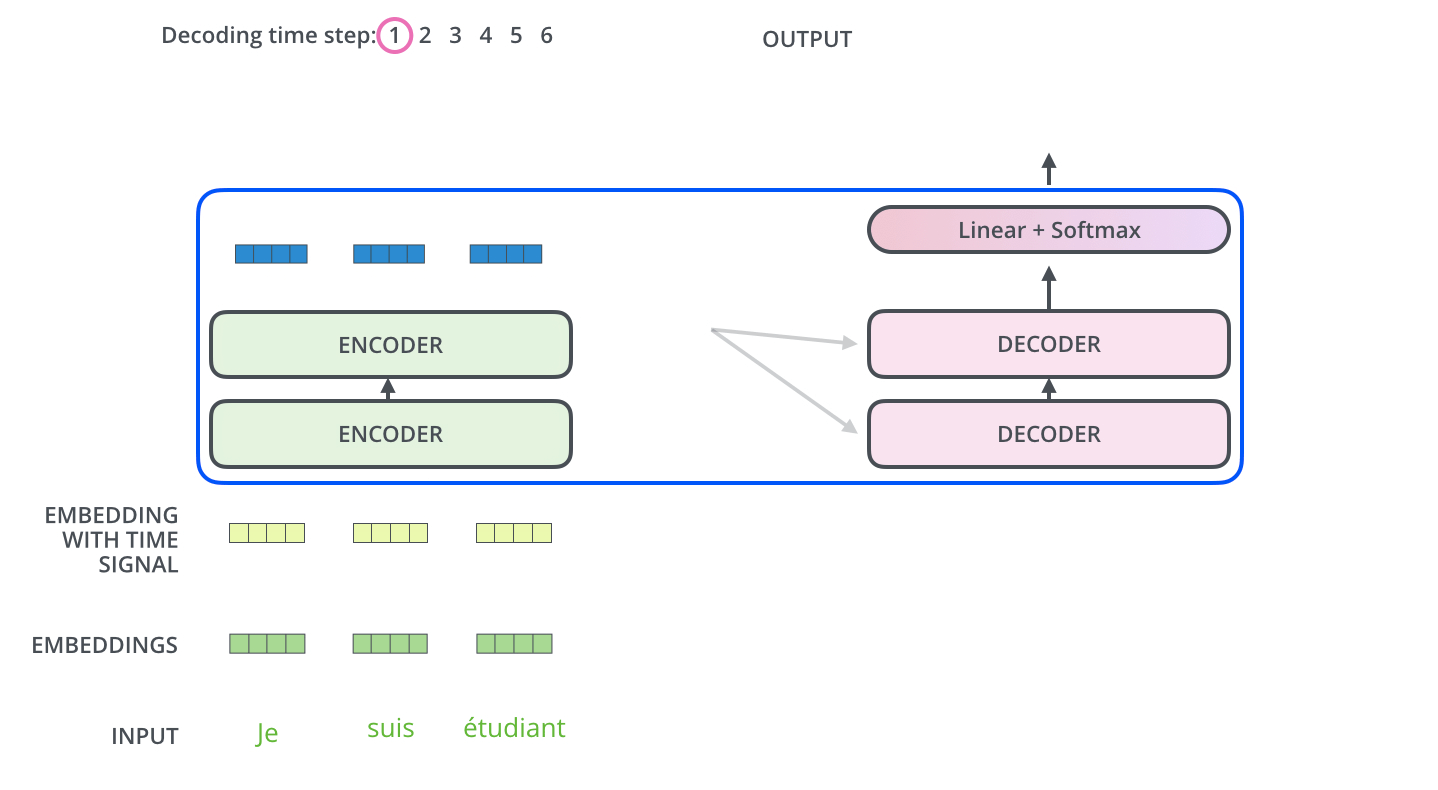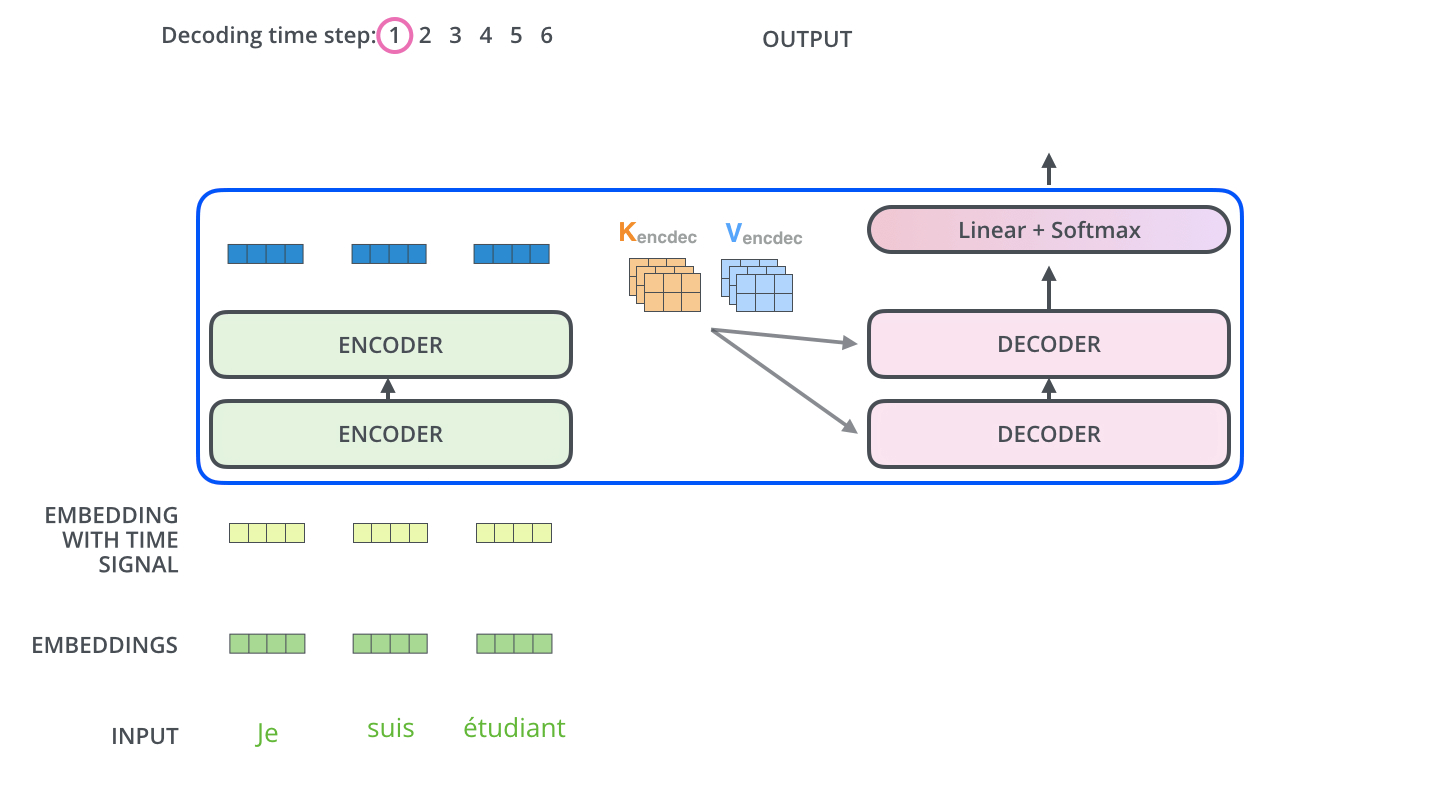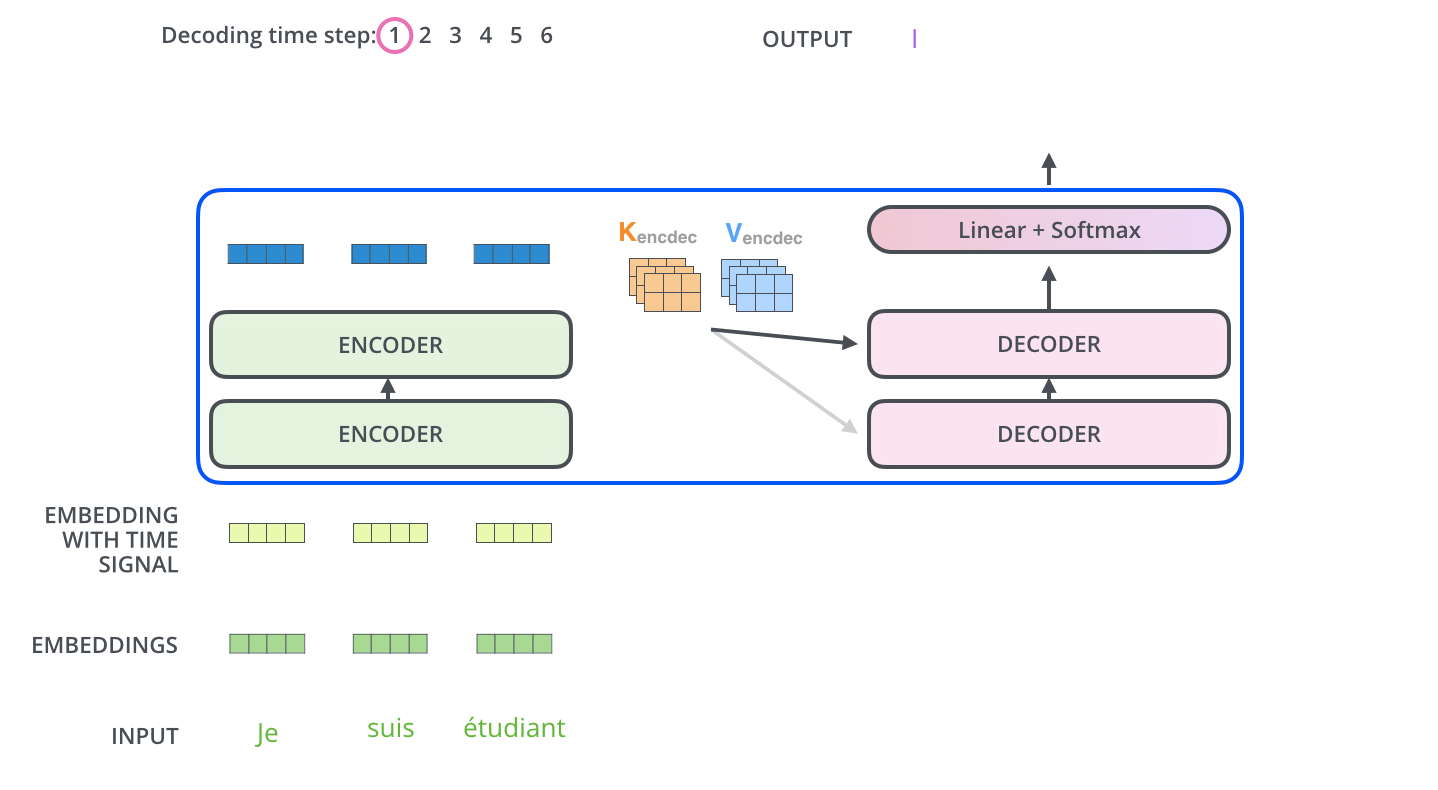
重复直到输出特殊符号 <eos>。每步输出喂给下一时间步的底层 decoder;decoder 输入同样要做嵌入 + 位置编码。
Decoder 的自注意力与 encoder 略有不同:只能 attend 到当前位置之前的输出——通过对未来位置 mask(设为 -inf)再 softmax 实现。
「编码器-解码器注意力」与多头自注意力类似,但 Q 来自下层 decoder,K/V 来自 encoder 栈输出。
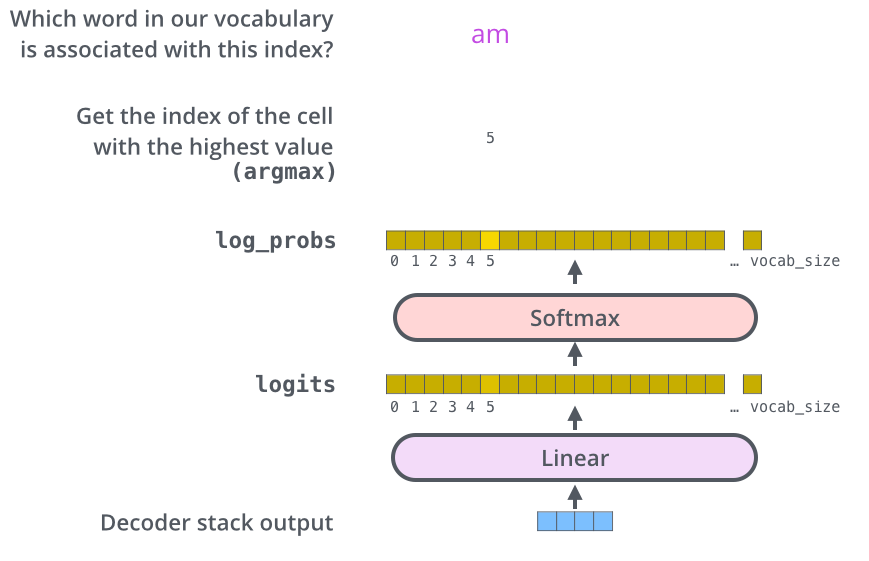
Decoder 栈输出浮点向量。如何变成词?经线性层再Softmax。
线性层把 decoder 输出投影到很大的 logits 向量。假设词表有 10,000 个英文词,logits 就有 10,000 维,每维对应一个词的分。
Softmax 把分数变成概率(非负、和为 1),取概率最大的词作为该步输出。
完整前向传播讲完后,简要看训练直觉。未训练模型走同样前向,但有标签可对比输出。
假设词表只有 6 个词:a、am、i、thanks、student、<eos>(句末)。
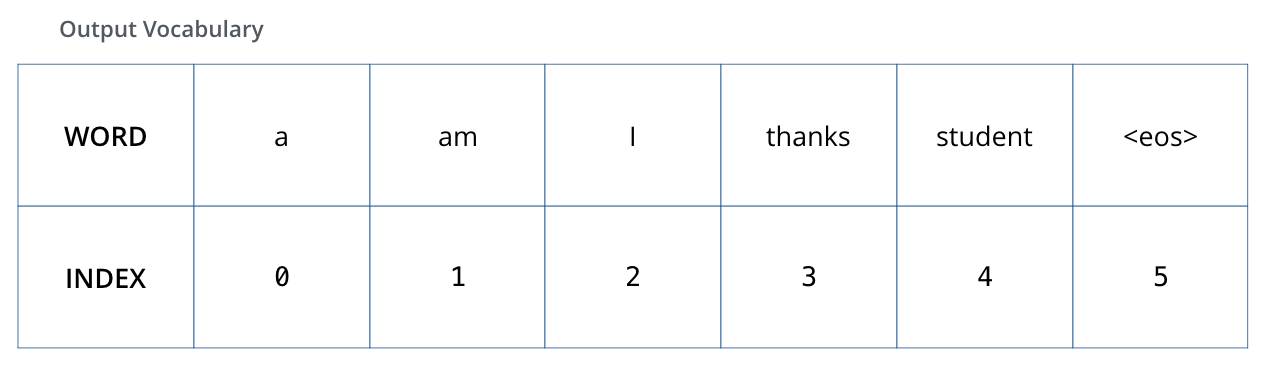
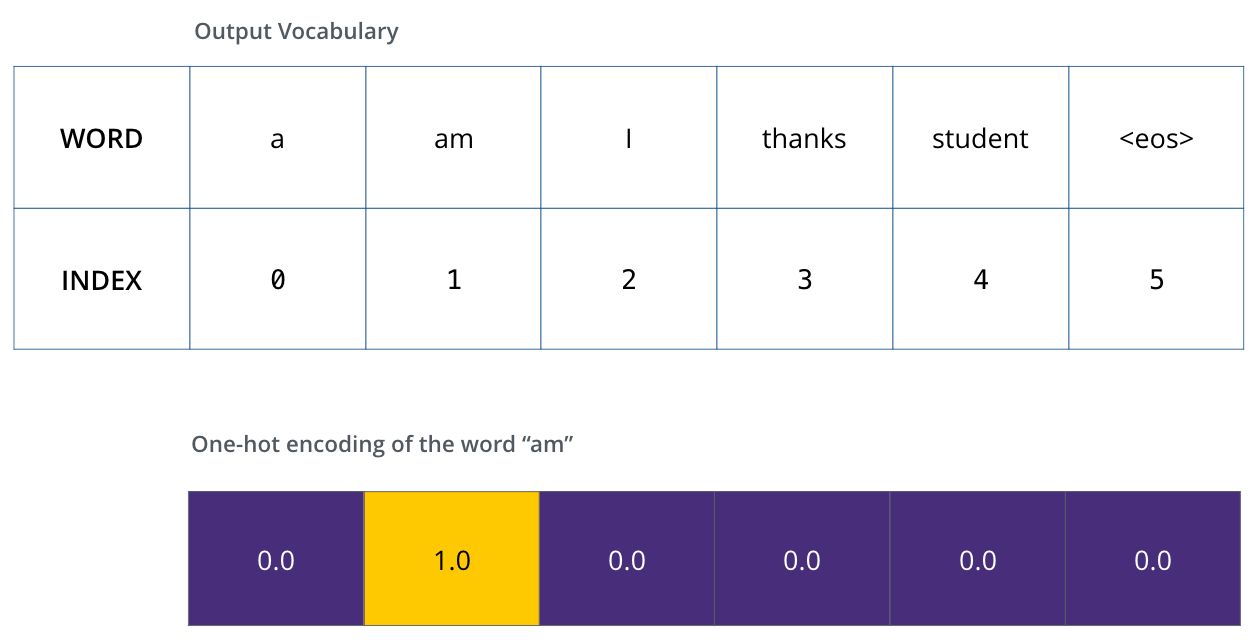
每个词用同样宽度的 one-hot 向量表示,例如 am:
训练第一步:把 merci 译成 thanks。我们希望输出分布在 thanks 上概率最高,但未训练模型只会给出随机分布。
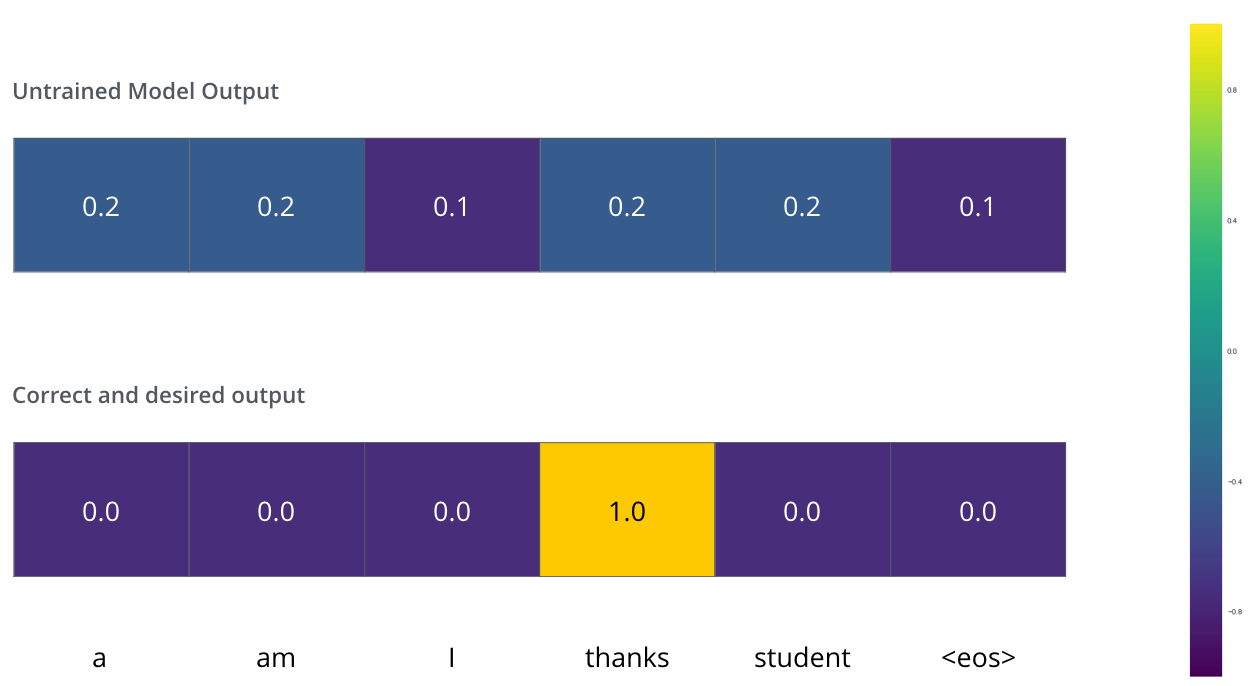
比较两个概率分布常用交叉熵或 KL 散度(文中简化为相减示意)。
更 realistic 的例子:输入 je suis étudiant,期望输出 i am a student。模型应逐步输出分布,使第 1 步峰值在 i,第 2 步在 am……第 5 步在 <eos>。
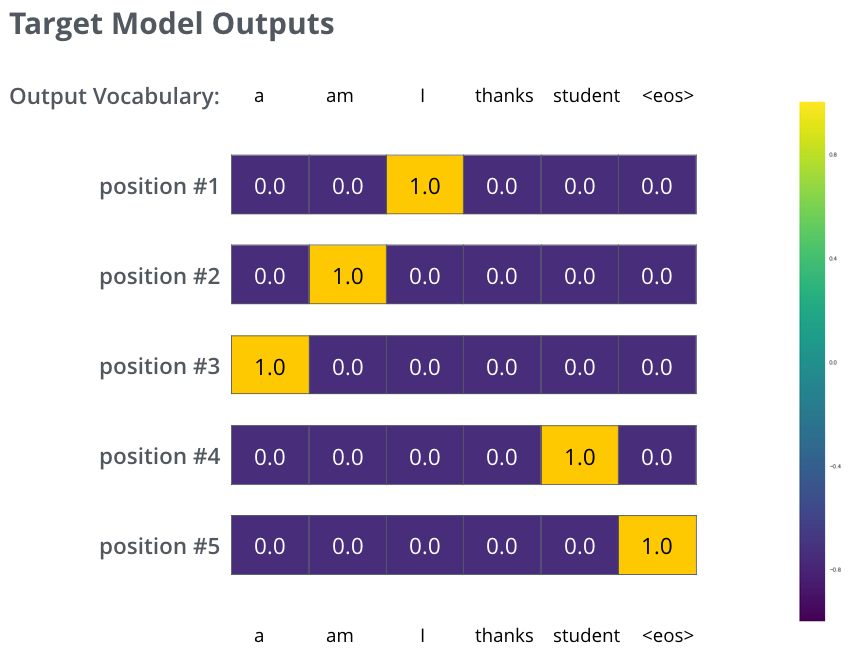
充分训练后,希望分布接近目标:
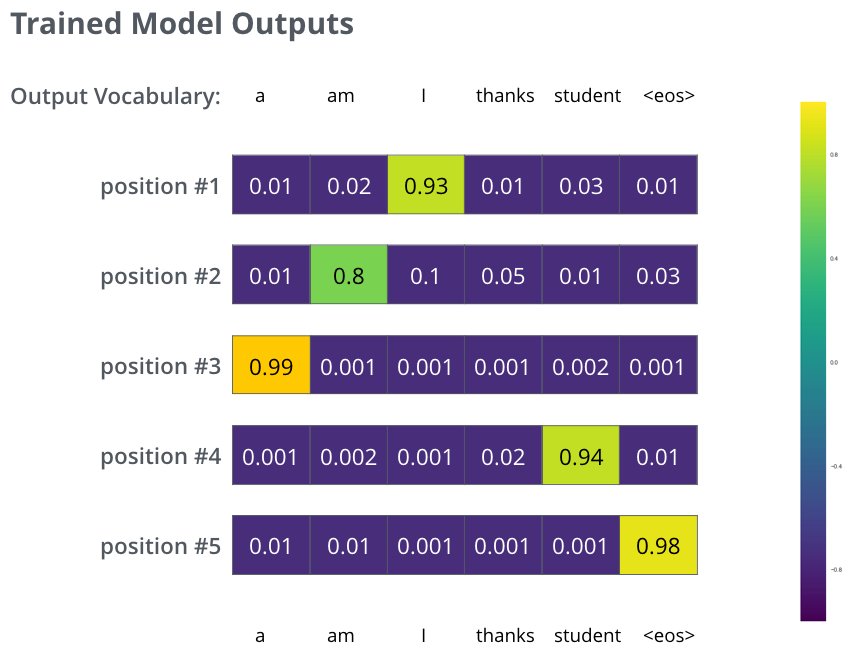
推理时可每步取概率最大的词(贪心解码),或保留 top-k 候选并行扩展(束搜索 beam search,如 beam_size=2 同时保留两条未完成假设)。二者都是可调超参数。
若本文帮你入门 Transformer,建议:
感谢 Illia Polosukhin、Jakob Uszkoreit、Llion Jones、Lukasz Kaiser、Niki Parmar、Noam Shazeer 对原文草稿的反馈。