htop 深度解析:理解 Linux 系统监控的每一个指标
一篇三次登上 Hacker News 首页的文章系统解释了 htop 中每个指标的含义。从 Load Average 的指数衰减移动平均本质,到 D 状态进程导致高负载低 CPU 的现象,再到 /proc 文件系统作为所有监控工具的数据来源,这篇文章是 Linux 系统管理的必读材料。
htop 是 Linux 系统管理员的瑞士军刀,但很多人只是看一眼 CPU 和内存条就开始操作。一篇三次登上 Hacker News 和 /r/sysadmin 首页的文章系统解释了 htop 中每个指标的真实含义,揭示了 Linux 进程管理的深层机制。
Load Average:不是你想的平均
负载平均值(Load Average)的三个数字分别代表过去 1 分钟、5 分钟、15 分钟的平均负载。但关键在于:负载 = 正在运行的进程数 + 不可中断睡眠(D 状态)的进程数,且本质是指数衰减移动平均,不是简单算术平均。
1 分钟负载 = 63% 来自最近 1 分钟 + 37% 来自系统启动以来的历史。这意味着负载对近期变化更敏感,但也会被历史拖累。
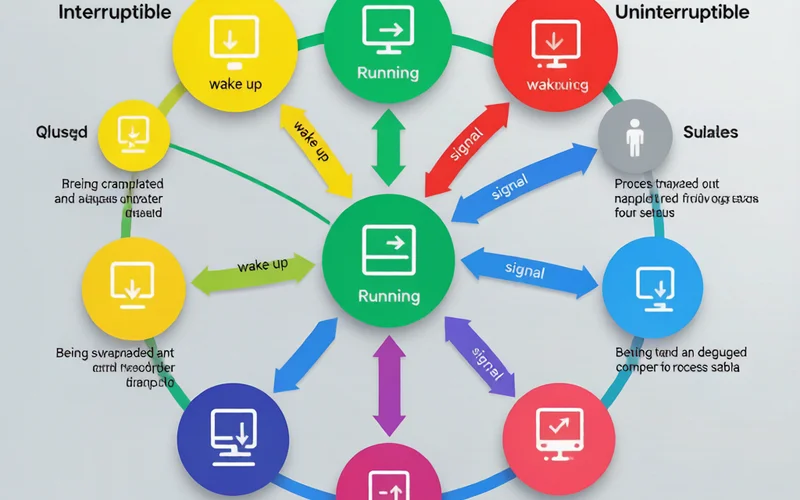
图1:Linux 进程状态转换图——R/S/D/Z/T 之间的流转
常见误区:负载 1.0 在双核机器上不等于 50% CPU 使用率,因为负载还包含 D 状态进程(通常在等待 I/O),不完全等同于 CPU 使用率。精确 CPU 使用率应使用 mpstat。
内存指标:VIRT vs RES vs SHR
| 指标 | 含义 | 关键点 |
|---|---|---|
| VIRT/VSZ | 虚拟内存总量 | 包括映射但未使用的页面,大多数情况下参考价值不大 |
| RES/RSS | 物理内存中使用部分 | 可能与其他进程共享;fork 后因 copy-on-write 会虚高 |
| SHR | 共享内存大小 | 反映可能与其他进程共享的内存 |
| MEM% | 物理内存占比 | RES / 总RAM × 100% |

图2:VIRT/RES/SHR 三层内存指标的含义对比
进程状态:D 状态是最容易被误解的
D 状态(Uninterruptible Sleep)是系统管理员最头疼的状态。进程在等待 I/O 操作完成,无法被 kill——即使 kill -9 也无效。D 状态进程贡献负载但不消耗 CPU,这就是"高负载低 CPU"现象的常见原因。
其他状态:R(运行中)、S(可中断睡眠)、Z(僵尸——已终止但父进程未回收,不占内存只占 PID,无法直接 kill,需 kill 父进程)、T(被信号停止)、t(被调试器跟踪)。
Niceness 和 Priority 的关系
NI(用户空间优先级,-20 到 19)和 PRI(内核空间优先级,0-139)的关系:PR = 20 + NI。NI 范围 -20 到 +19 映射到 PR 100 到 139。"越 nice 的进程越让路"——NI 值越高,优先级越低。
/proc 文件系统:一切监控工具的数据之源
htop、top、ps 等工具本质上都是在读取 /proc 文件系统:
/proc/:启动命令(用/cmdline \0分隔参数)/proc/:包含 UID、状态等/status /proc/uptime:系统运行时间和空闲时间/proc/loadavg:负载平均值
善用 strace 可以追踪程序打开了哪些 /proc 文件,深入理解监控工具的实际行为。例如 strace uptime 会发现 uptime 只是读取 /proc/uptime 文件。
信号知识:SIGKILL vs SIGTERM
SIGKILL(信号 9)不可被捕获或忽略——这是最后的手段。SIGTERM(信号 15)可以被捕获处理——程序可以优雅退出。SIGINT(信号 2,等同 Ctrl+C)也可以被捕获。了解信号行为对于系统管理至关重要:永远先尝试 SIGTERM,给进程优雅退出的机会,只在必要时使用 SIGKILL。
关联推荐
- GitHub Actions 全面拥抱 AI Agent — CI/CD 系统监控与自动化
- 阿里巴巴禁止 Claude Code — 企业工具安全与系统监控
- MCP 模型上下文协议 — 系统工具的标准化通信
评论 (0)
加载评论中…