数据库分区设计:按主键分区而非时间列,告别手动运维
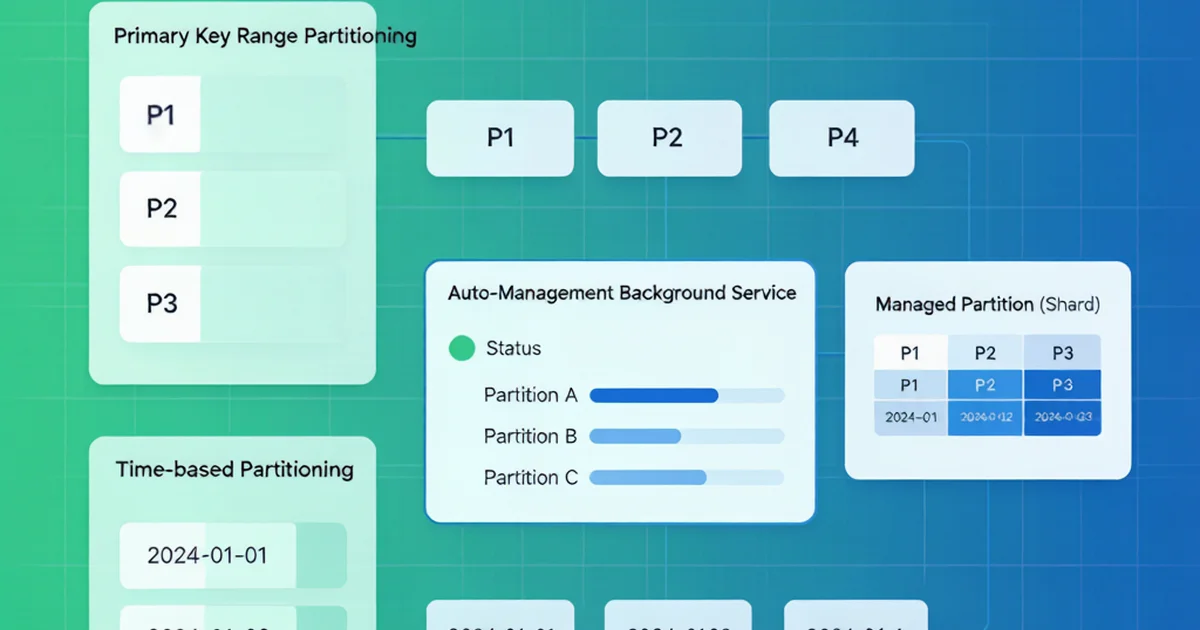
一篇引起广泛讨论的文章主张按主键而非 created_at 时间列进行数据库分区,通过后台服务自动管理分区边界。这样查询无需修改即可自动获得分区裁剪,避免泄漏抽象和查询性能退化。
数据库分区是处理大数据量的常见手段,但分区键的选择往往决定了系统是"自动运行"还是"需要 babysit"。一篇在 Hacker News 上引起广泛讨论的文章提出了一个反直觉的建议:按主键分区,而非按 created_at 时间列分区。
按 created_at 分区的陷阱
按时间列分区看似自然——每月一个分区,老数据归档方便。但它带来了一个严重的副作用:主键被迫变为 PRIMARY KEY (id, created_at),这意味着任何不包含 created_at 过滤条件的查询会扫描所有分区。
一个 WHERE id = 12345 查询从一次索引查找退化为 36 次索引查找(假设有 36 个月度分区)。更糟糕的是,id 不再保证唯一——数据库可以接受两个相同 id 但不同时间戳的行。
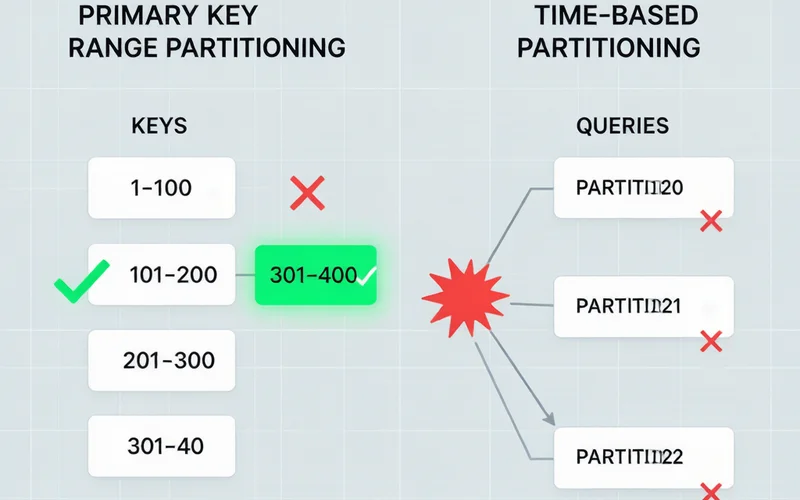
图1:按主键分区(左)自动裁剪 vs 按时间分区(右)扫描所有分区
团队的"修复"方式通常是在每个查询中加上日期过滤,但这是一种泄漏抽象——存储决策变成了每个调用者必须遵守的契约。没有报错,只有慢查询,通常在仪表盘超时后才被发现。
推荐策略:按主键 RANGE 分区
按 id(BIGINT AUTO_INCREMENT)进行 RANGE 分区的优势:
- 主键本身单调递增,满足范围分区需求
- 几乎所有查询都按
id过滤,自动获得分区裁剪(partition pruning) - 主键保持
PRIMARY KEY (id),唯一性不受影响 - 应用代码零改动
时间对齐但不在键中使用日期
按 id 分区不等于放弃时间对齐。后台服务通过查询推导时间对应的 ID 边界:
SELECT MAX(id) FROM orders WHERE created_at < '2026-03-01'这样分区名称可以是 p2026_03,内容大致对应 2026 年 3 月的数据。created_at 仅在 DDL 时使用一次,不进入主键,不进入查询 WHERE 子句。
后台自动管理服务
一个轻量级定时服务负责:
| 步骤 | 说明 |
|---|---|
| 盘点 | 读取当前分区布局、名称、边界、行数 |
| 大小检查 | 活跃分区超过阈值时触发切割 |
| 边界选择 | 查询时间对应的 ID 边界 |
| 拆分 | REORGANIZE PARTITION 拆分兜底分区 |
| 保留期清理 | 将保留窗口转为 ID 边界,删除过期分区 |
| 并发保护 | advisory lock 防止多实例同时操作 |
核心决策原则
在选择分区键之前,先问:哪个列已经存在于每个重要查询中?
- OLTP 系统 → 答案通常是主键,按主键分区零成本
- 多租户系统且每个查询都带
tenant_id→ 按tenant_id分区合理 - 真正的时序工作负载且每个查询都按日期过滤 → 按时间列分区合理
最糟糕的做法:按一个不在查询中的列分区,然后逆向改造查询层去适配它——最终以 AND created_at >= ? 遍布所有与日期无关的查询而告终。
关联推荐
- GitHub Actions 全面拥抱 AI Agent — 自动化运维的 AI 化
- 2026 AI 编程代理格局 — AI 在基础设施管理中的应用
- MCP 模型上下文协议 — 数据访问协议标准
评论 (0)
加载评论中…