LTAP 架构:Databricks 让 Postgres 以 Parquet 格式统一事务与分析
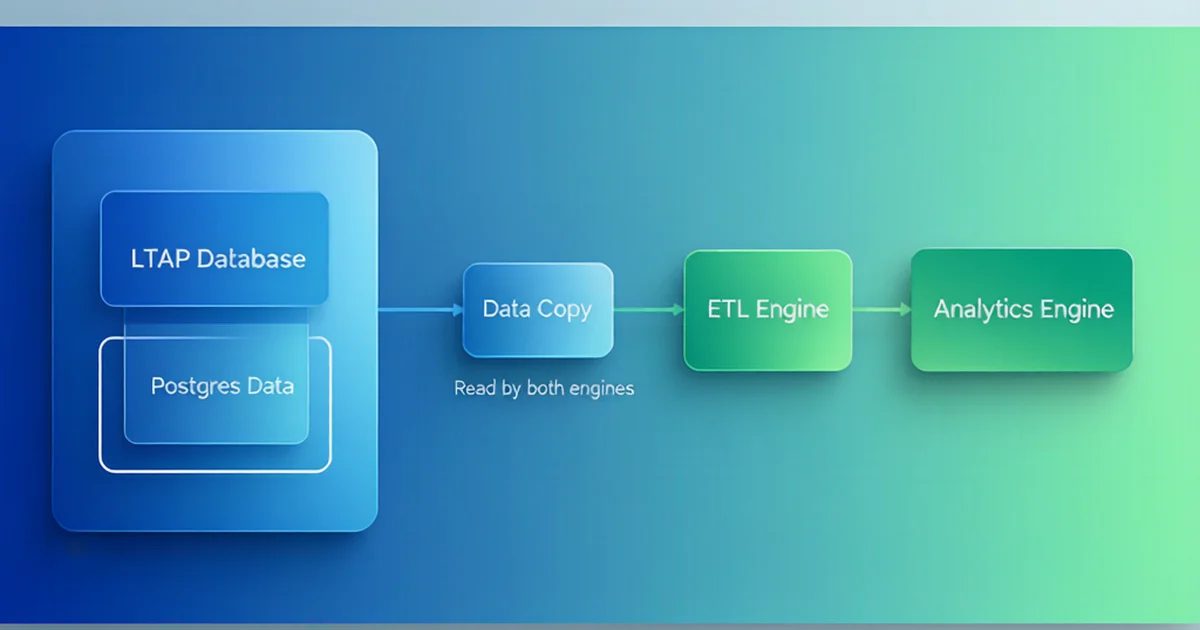
Databricks 推出 LTAP(Lake Transactional/Analytical Processing)架构,将 Postgres 事务数据在物化时即转换为 Parquet 列式格式,一份数据同时供事务引擎和分析引擎读取,彻底消除 CDC 管道的复杂性和延迟。
Databricks 联合创始人 Reynold Xin 撰文阐述了 LTAP 架构,其核心创新在于:将操作型数据以开放列式格式(Parquet)存储一份,同时供 Postgres 事务引擎和 Lakehouse 分析引擎读取,无需 CDC 管道或第二份数据副本。
核心理念:在存储层统一
LTAP 不走传统 HTAP 的"一个引擎同时做事务和分析"路线,而是保留各自最佳引擎——Postgres 负责事务(完整 ACID 语义),Lakehouse 引擎负责分析——在存储层统一数据格式。
架构基础:Lakebase 存储外置化
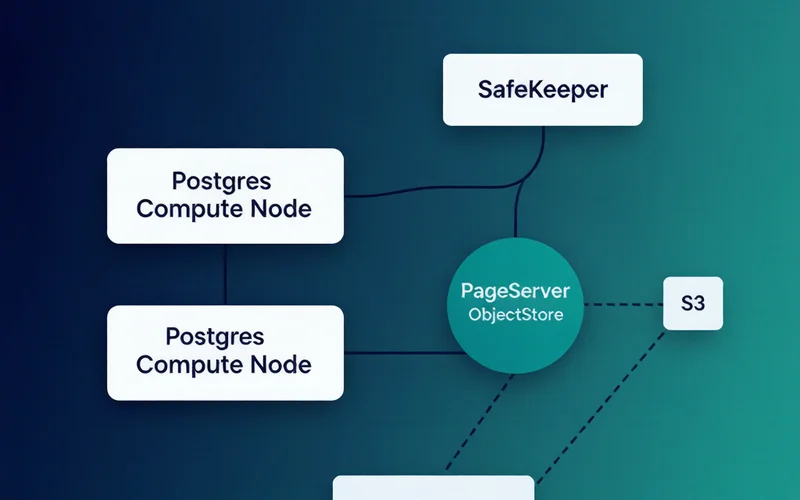
图1:LTAP 架构——Postgres 数据以 Parquet 格式统一事务与分析
LTAP 建立在 Lakebase 架构之上,将传统 Postgres 的单机存储拆分为两个独立服务:
| 组件 | 功能 | 替代的传统组件 |
|---|---|---|
| SafeKeeper | 分布式 WAL 存储,基于 Paxos 复制日志 | 本地磁盘上的 WAL |
| PageServer | 分布式数据文件服务,将页面物化到云对象存储 | 本地磁盘上的数据文件 |
Postgres 计算节点因此变为无状态的,可自由启动、停止和复制。
列式格式物化
PageServer 在将数据物化到对象存储时,执行关键的格式转换:将 Postgres 的行格式数据转码为 Parquet 列式布局,同时精确保留 Postgres 语义:
- 类型系统:大多数 Postgres 类型直接映射到 Parquet 原生类型;少数无法无损转换的值(如 NaN、±Infinity、超大 NUMERIC)通过结构化溢出字段保留原始文本表示
- 多版本控制(MVCC):每个行版本携带其物理堆地址,保留快照隔离和时间点恢复能力
实时数据读取机制
LTAP 解决了"新鲜度"这一关键挑战:
- 分析查询启动时,向 Postgres 请求当前 LSN
- 用该 LSN,分析引擎直接从对象存储读取已物化的绝大多数数据
- 尚未物化的最新变更从 PageServer 获取并在上层合并
- Postgres 本身不服务任何分析读流量(仅返回一个 LSN 值)
相比 CDC 的优势
| 特性 | CDC / 镜像 | LTAP |
|---|---|---|
| 数据副本数量 | 两份 | 一份 |
| 需要选择同步表 | 是,需显式选择 | 否,自动覆盖所有表 |
| 复制延迟 | 存在 | 无,实时读取 |
| 管道维护 | 需构建、监控 | 无需 ETL 管道 |
此外,列式数据压缩率通常超过 10 倍,大幅减少网络传输量。行到列式的转码由 PageServer 层的空闲 CPU 完成,不影响 Postgres 事务服务。
HTAP 为什么失败,LTAP 为什么不同
传统 HTAP 失败的三大原因:功能不完整、缺乏生态、无性能隔离。LTAP 的应对:使用成熟的 Postgres 和 Lakehouse 引擎(功能完整),直接利用各自庞大的驱动和工具生态,事务和分析使用独立计算资源互不干扰。
关联推荐
- GitHub Actions 全面拥抱 AI Agent — CI/CD 与数据架构的自动化
- 2026 AI 编程代理格局 — AI 工具与数据基础设施的结合
- MCP 模型上下文协议 — 数据访问的统一协议标准
评论 (0)
加载评论中…